Encode
This is a mock-up showing a PDF that highlights the principle that logical elements should be selectable in queries and interim results.
Intelligibility - Defeasibility
Dependent Types
Rule 1. Formation
Where
where in the premise there is no initial assumption.
No initial assumption is indefeasible.
Dependent sum formation rule notation source: David Corfield, Modal Homotopy Type Theory: The Prospect of a New Logic for Philosophy(Oxford University Press, 2020), p. 55.
In terms of the subtlety of logical elements, contrast this with the way the turnstile changes direction on this website's landing page, here ΑΒΓΔ.XYZ.
The following is mock-up output from the parse of a positive sequent tree showing the groups extracted from some of the four rows. I had to edit this by hand as AI and code still makes many errors.
This is the compiled source for the complete positive sequent tree.
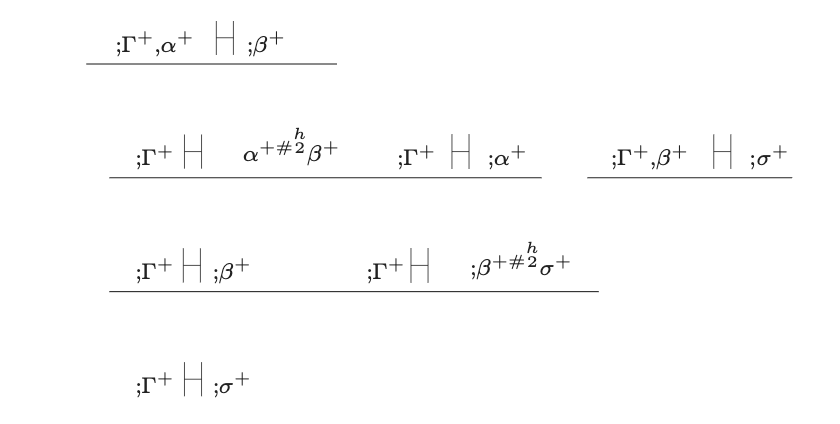
Diagram adapted from James Trafford, Meaning in Dialogue: An Interactive Approach to Logic and Reasoning (Springer, 2017), p. 186.
I come to AI from psychoanalysis. With over three decades of clinical work shaping how I think about language, change, and responsibility. In an alternative career that I pursued for about a decade, I was an object‑oriented Java back-end specialist.
My roles were in industry, but I also taught software engineering at the University of Greenwich for a year.
Recently, I have become engaged in a synthesis of interests focused on AI‑safety research, category theory, and various parties, such as clinicians, who want to avail themselves of the benefits of understanding these computational tools.
My goal is to build a neurosymbolic architecture in which agentic AI systems act only as untrusted proposal generators around a formally specified, co‑constructive logic kernel with explicit provenance and experimental, optional cryptographic anchoring. The aim is to give research communities in mental health, AI safety, and software engineering a way to represent and revise their claims, norms, and disagreements as evolving logical structures, and to add tools for transparent, auditable reasoning in scientific and clinical practice, where the assessment of critical risk is essential.
The Encode fellowship’s combination of compute, mentorship, and access to ARIA‑adjacent ecosystems would enable me to move from conceptual design to large‑scale experiments. With substantial compute and access to corpora through Mathematics for Safe AI, Safeguarded AI, and neighbouring AI‑safety, clinical literature and relevant training data, I would use this architecture to map how notions of risk, alignment, harm, and responsibility are introduced, contested, and stabilised across communities. This connects model‑level safety work to the higher‑level question of how societies and expert groups actually reason about, and modify, their processes and beliefs in the context of powerful AI systems.
The work is with open scientific corpora such as S2ORC/OpenAlex and PubMed Central, focusing on slices related to AI safety, Safeguarded AI, mental health, and formal methods. The process is not a single run, but repeated, comparative passes of using the neurosymbolic pipeline over these corpora—extracting claims, building logical and provenance graphs, and varying the agentic “edge” (models, prompts, orchestration) while keeping the formal kernel fixed. This facilitates the study of how different agent configurations change and how notions of risk, harm, and responsibility are represented across logically modelled communities at scale.
The logical modelling is isolated, enabling the study of changes to these models.
This fellowship could later grow into an open research commons or, if there is sufficient demand and fit with ARIA’s mission, the nucleus of a focused research organisation dedicated to epistemic and provenance infrastructure for agentic AI.
The technical project I am most proud of is the design of a “logic‑centric” agent architecture that treats AI assistants as untrusted front‑ends to a formally specified proof engine. AI assistant‑agents are wrapped around a typed sequent‑calculus core: a co‑constructive proof/refutation kernel that accepts only structured inputs and produces checkable proof objects, while all free‑text interaction is mediated by an “agentic edge” that can suggest but never alone ratify inferences. A provenance layer, maintaining sequential order, records formulas, sequents, proofs, and their “supports/refutes/alternative” relations back to source documents, so that any reasoning step can be re‑checked. Each agent has its own internal logic and interface, and interactions between agents become compositional transformations between their local theories. At an early stage, this can be prototyped as an Obsidian‑integrated research tool.
I value this work because it demonstrates a concrete neurosymbolic alternative to treating large models as opaque authorities: it shows how to separate suggestion from endorsement and make epistemic commitments explicit and auditable.
Substantial compute would enable two forms of stress‑test.
- Running large‑scale experiments over evolving bodies of work—such as AI‑safety literature or software artefacts—to see how formal guarantees and cryptographic commitments can constrain what AI tools “claim”.
- Employing methods like those in Karpathy's Autoresearch (Claude.md manifest) that iterate over alternative engine and prompt configurations, defining success for experimental purposes.
The project itself is explicitly cross‑disciplinary: it models expert communities as evolving “local topoi”, drawing on category theory, social choice, game theory and information theory, while remaining grounded in the ethical and epistemic constraints of psychoanalytic and clinical practice. I am comfortable translating between conceptual languages (clinical, mathematical, and engineering) and designing structures where different communities’ internal logics can interact without being reduced to a single crude metric.
Know what I want to build
Use the 12 months to build and stress‑test a “logic‑centric” agentic research assistant, initially as a proof‑of‑concept integrated into tools like Obsidian or similar research environments. The core idea is to separate suggestion from endorsement: language‑model‑based agents can propose claims, links, and arguments, but all logically significant steps must pass through a formally specified, co‑constructive proof/refutation kernel that produces checkable proof objects and explicit provenance. This would allow individual researchers and small teams to see not just what an AI system says, but also how its suggestions relate to prior claims, what evidence it relies on, and where the uncertainties and open questions lie.
Deliver three things in the year: (1) a minimal, well‑specified logical kernel and provenance schema that can host multiple internal logics (e.g. intuitionistic, co‑constructive, modal); (2) an agent orchestration layer that treats different tools and communities as “local topoi” with their own signatures, so that interactions between them are compositional and inspectable; and (3) a working prototype that can be used on real corpora, starting with AI‑safety, safeguarded‑AI, and related scientific literatures.
To build a small but solid infrastructure that makes epistemic commitments explicit and auditable, and that can later be scaled up—whether as an open research commons, a specialised safety tool, or the seed of a more formal, focused research organisation.